LLM Gateway API
LLM Gateway API Documentation
Version: 1.2.2
Table of Contents
Introduction
Access and build applications seamlessly with your preferred model from a comprehensive pool of LLMs available through the LLM Gateway, supporting a diverse range of capabilities, including text generation, multimodal capabilities, image generation, speech-to-text transcription, and embedding generation. Our platform ensures your applications are safeguarded with robust guardrails while enhancing prompt responses through advanced caching mechanisms. Simply generate an LM-API key via the Kadal platform, and you're ready to deploy. To accelerate your development, we also offer a curated collection of demo implementation scripts tailored for all supported models.
Architecture
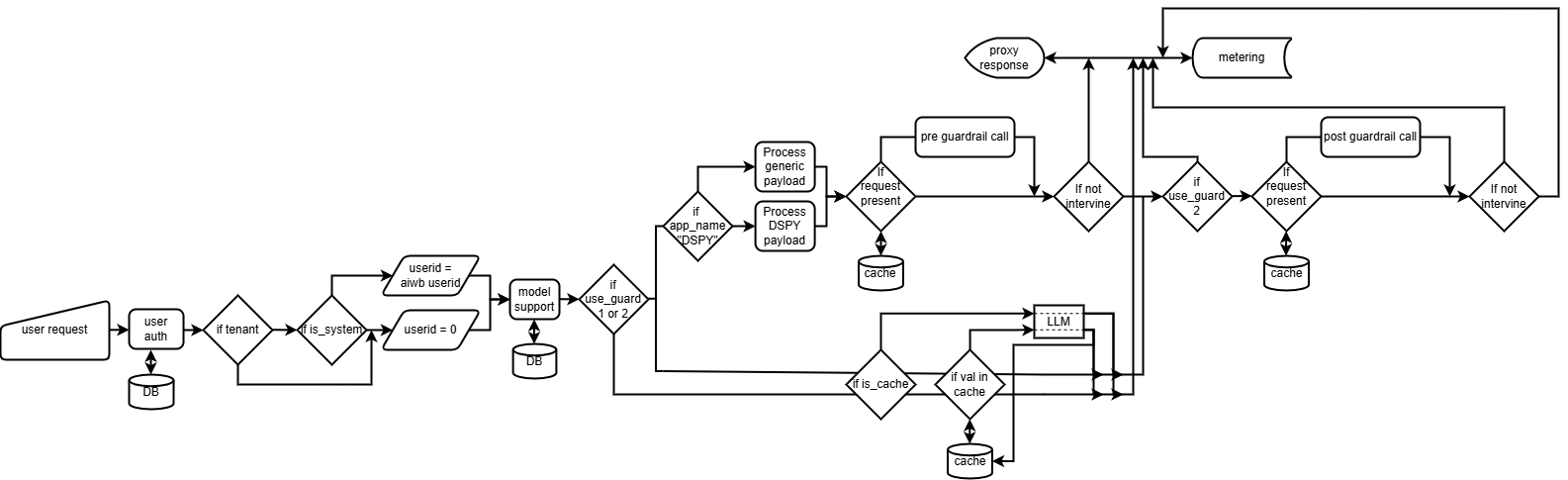
Providers
Azure OpenAI
| Models | Context Length | Price (M Tokens) | Active / Deprecated | Model Support |
|---|---|---|---|---|
| gpt-4.1 New | 100K | Input: $2.00, Output: $8.00 | Active | text |
| gpt-4.1-mini New | 100K | Input: $0.40, Output: $1.60 | Active | text |
| gpt-4.1-nano New | 100K | Input: $0.10, Output: $0.40 | Active | text |
| o3-mini New | 200K | Input: $1.10, Output: $4.40 | Active | text |
| gpt-4o-mini | 128K | Input: $0.165, Output: $0.66 | Active | text, image |
| gpt-4o | 128K | Input: $2.75, Output: $11 | Active | text, image |
| o1-mini | 128K | Input: $3.30, Output: $13.20 | Active | text, image |
| o1 | 200K | Input: $16.50, Output: $66 | Active | text, image |
| gpt-4-0125-preview | 128K | Input: $10, Output: $30 | Deactivaed | text |
| gpt-4-vision-preview | 128K | Input: $10, Output: $30 | Deactivaed | text, image |
| gpt4-vision-preview | 128K | Input: $10, Output: $30 | Deactivaed | text, image |
| gpt-4 | 128K | Input: $10, Output: $30 | Deactivaed | text |
| gpt-35-turbo-1106 | 16K | Input: $1, Output: $2 | Active | text |
| gpt-35-turbo | 16K | Input: $1, Output: $2 | Active | text |
Vertex AI
| Models | Context Length | Price (k Character) | Active / Deprecated | Model Support |
|---|---|---|---|---|
| Gemini-2.0-flash New | Max input tokens: 1,048,576 Max output tokens: 8,192 | Input: $0.0375/M char, Output: $0.15/M char | Active | text, image |
| Gemini-2.0-flash-lite New | Max input tokens: 1,048,576 Max output tokens: 8,192 | Input: $0.01875/M char, Output: $0.075/M char | Active | text, image |
| gemini-1.5-flash | Max input tokens: 1,048,576 Max output tokens: 8,192 | Input: $0.00001875, Output: $0.000075 | Active | text, image |
| gemini-1.5-pro | Max input tokens: 2,097,152 Max output tokens: 8,192 | Input: $0.0003125, Output: $0.00125 | Active | text, image |
| gemini-1.0-pro | Max input tokens: 32,760 Max output tokens: 8,192 | Input: $0.000125, Output: $0.000375 | Deactivaed | text, image |
AWS Bedrock
Anthropic:
| Models | Context Length | Price (k Tokens) | Active / Deprecated | Model Support |
|---|---|---|---|---|
| anthropic.claude-3-5-haiku-20241022-v1:0 | 200k | Input: $0.0008, Output: $0.004 | Active | text, image |
| anthropic.claude-3-haiku-20240307-v1:0 | 200k | Input: $0.00025, Output: $0.00125 | Active | text, image |
| anthropic.claude-3-sonnet-20240229-v1:0 | 200k | Input: $0.003, Output: $0.015 | Active | text, image |
| anthropic.claude-3-5-sonnet-20240620-v1:0 | 200k | Input: $0.003, Output: $0.015 | Active | text, image |
| anthropic.claude-3-opus-20240229-v1:0 | 200k | Input: $0.015, Output: $0.075 | Active | text, image |
Llama:
| Models | Context Length | Price (k Tokens) | Active / Deprecated | Model Support |
|---|---|---|---|---|
| us.meta.llama3-3-70b-instruct-v1:0 New | 128k | Input: $0.00072, Output: $0.00072 | Active | text, image |
| us.meta.llama3-2-90b-instruct-v1:0 | 128k | Input: $0.00072, Output: $0.00072 | Active | text, image |
| us.meta.llama3-2-11b-instruct-v1:0 | 128k | Input: $0.00016, Output: $0.00016 | Active | text, image |
| meta.llama3-1-405b-instruct-v1:0 | 128k | Input: $0.0024, Output: $0.0024 | Active | text |
| meta.llama3-1-70b-instruct-v1:0 | 128k | Input: $0.00072, Output: $0.00072 | Active | text |
| meta.llama3-1-8b-instruct-v1:0 | 128k | Input: $0.00022, Output: $0.00022 | Active | text |
| meta.llama3-70b-instruct-v1:0 | 128k | Input: $0.00265, Output: $0.0035 | Active | text |
| meta.llama3-8b-instruct-v1:0 | 128k | Input: $0.0003, Output: $0.0003 | Active | text |
Nova:
| Models | Context Length | Price (k Tokens) | Active / Deprecated | Model Support |
|---|---|---|---|---|
| us.amazon.nova-micro-v1:0 | 128k | Input: $0.000035, Output: $0.00014 | Active | text |
| us.amazon.nova-lite-v1:0 | 300k | Input: $0.00006, Output: $0.00024 | Active | text, image, Docs, Video |
| us.amazon.nova-pro-v1:0 | 300k | Input: $0.0008, Output: $0.0032 | Active | text, image, Docs, Video |
Additional Configuration Options
Individual User/Group
Configuration Options
is_cache
- Default:
1(caching is enabled). - Set to
0: Disables caching for API responses, ensuring each request fetches fresh results.
use_guard
- Default:
1(guardrails are enabled for input or output by default). - Set to
0: Completely disables guardrails. - Set to
2: Explicitly enables both input and output guardrails, providing maximum safeguards.
app_name
- A string specifying the application context.
- Include this only when the application is
DSPY.
lm_key = 'YOUR_LM_KEY'
userdata = {
"is_cache": 0,
"use_guard": 2,
"app_name": "DSPY",
}
User_LM_Key = f"{lm_key}/{userdata}"
For Kadal Tenent:
is_cache
- Default:
1(caching is enabled). - Set to
0: Disables caching for API responses, ensuring each request fetches fresh results.
use_guard
- Default:
1(guardrails are enabled for input or output by default). - Set to
0: Completely disables guardrails. - Set to
2: Explicitly enables both input and output guardrails, providing maximum safeguards.
app_name
- A string specifying the application context.
- Include this only when the application is
DSPY.
Bot_Id
- A string representing the unique identifier for the bot.
- Example:
"cf72e8cb-ef5b-4c7f-9792-685e7100a94f".
Query_Id
- A string or integer representing the unique identifier for the current query.
- Example:
"24".
word_count_sent
- The number of words sent in the request.
- Example:
50.
word_count_received
- The number of words received in the response.
- Example:
100.
toxicity
- Indicates the toxicity level of the response.
- Example:
"Toxic".
sentiment
- Indicates the sentiment of the response.
- Example:
"Positive".
app_name
- A string specifying the application context.
- Include this key only when the application is
DSPY.
userid
- A string or integer representing the unique identifier for the user.
- Example:
"100".
is_system
- A boolean value indicating if the request is system-generated.
- Default:
True.
lm_key = 'YOUR_LM_KEY'
userdata = {
userdata = {
"is_cache":0,
"use_guard":0,
"Bot_Id": "cf72e8b-ef5b-4c7f-9792-685e7100a94f",
"Query_Id": "24",
"word_count_sent": 50,
"word_count_received": 100,
"toxicity": "Toxic",
"sentiment": "Positive",
"app_name": "DSPY", # use only when the app is DSPY
"userid": "100",
"is_system": False
}
}
Tenent_LM_Key = f"{lm_key}/{userdata}"
Code Examples
Azure OpenAI code Examples
from openai import AzureOpenAI
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
api_version="2024-02-15-preview"
client = AzureOpenAI(azure_endpoint=azure_endpoint,
api_version= api_version,
api_key=lm_key)
response = client.chat.completions.create(
model = "gpt-4o-mini",
temperature = 0.7,
messages=[
{"role": "user", "content": """Hello World"""}
])
print(response)
import requests # Or use httpx
import json
# Azure OpenAI Configuration
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
headers = {
'Content-Type': 'application/json',
'api-key': lm_key
}
# Request Body
body = {
'messages': [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Hello! How can I improve my productivity?'}
],
'model': 'gpt-4',
'temperature': 0.7
}
# Sending the Request
try:
response = requests.post(
f'{azure_endpoint}/openai/deployments/gpt-4/chat/completions?api-version=2024-02-15-preview',
headers=headers,
json=body
)
# Check for successful response
if response.status_code == 200:
print("Response:")
print(json.dumps(response.json(), indent=4))
else:
print(f"Error: {response.status_code} - {response.text}")
except Exception as e:
print(f"An error occurred: {e}")
curl --location 'https://api.kadal.ai/proxy/api/v1/azure/openai/deployments/gpt-4o/chat/completions?api-version=2024-02-15-preview' \
--header 'Content-Type: application/json' \
--header 'api-key: <YOUR_LM_KEY>' \
--data '{"model":"gpt-4o",
"temperature":0.7,
"messages":[
{"role": "user", "content": "Hello World"}
]}'
Multimodel Azure OpenAI Models
import base64 # Importing the base64 module to encode the image into Base64 format
# Function to encode an image into Base64
def encode_image(image_path):
"""
Encodes the image at the given path into a Base64 string.
Args:
image_path (str): Path to the image file to be encoded.
Returns:
str: Base64-encoded string of the image.
"""
with open(image_path, "rb") as image_file: # Open the image file in binary mode
# Read the file, encode its content to Base64, and decode it to a UTF-8 string
return base64.b64encode(image_file.read()).decode('utf-8')
# Encode the image at the specified path
base64_image = encode_image("sample.png")
# Importing necessary modules
from openai import AzureOpenAI # AzureOpenAI SDK for interacting with Azure OpenAI services
# Define Azure OpenAI endpoint and API key
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
# Specify the API version to use
api_version = "2024-02-15-preview"
# Initialize the AzureOpenAI client
client = AzureOpenAI(
azure_endpoint=azure_endpoint, # Azure OpenAI endpoint
api_version=api_version, # API version
api_key=lm_key # Azure OpenAI API key for authentication
)
# Prepare the chat request
response = client.chat.completions.create(
model="gpt-4o", # Specify the model to use (e.g., GPT-4 optimized)
temperature=0.7, # Control the randomness of the response (higher = more random)
messages=[
{
"role": "user", # Role of the message sender
"content": [
{"type": "text", "text": "What's in this image?"},
{
"type": "image_url", # Specify the type as an image URL
"image_url": { # Provide the image URL in Base64 format
"url": f"data:image/jpeg;base64,{base64_image}", # Embed the Base64-encoded image
},
},
],
}
]
)
# Print the response from the Azure OpenAI service
print(response)
Embedding models
from openai import AzureOpenAI # Importing the AzureOpenAI class
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
api_version = "2024-02-15-preview"
# Initialize the AzureOpenAI client
client = AzureOpenAI(
azure_endpoint=azure_endpoint,
api_version=api_version,
api_key=lm_key
)
# Generate embeddings
response = client.embeddings.create(
input="Your text string",
model="text-embedding-ada-002"
)
print(response.data[0].embedding)
Dall-e Models
from openai import AzureOpenAI # Importing the AzureOpenAI class
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
api_version = "2024-02-15-preview"
# Initializing the AzureOpenAI client with the endpoint, API version, and API key
client = AzureOpenAI(
azure_endpoint=azure_endpoint,
api_version=api_version,
api_key=lm_key
)
response = client.images.generate(
model="dall-e-3", # Specifying the model to use (DALL-E 3)
prompt="generate a cat", # The text prompt describing the image to generate
size="1024x1024", # The desired size of the image
quality="standard", # The quality setting for the generated image
n=1, # Number of images to generate
)
# Extracting the URL of the generated image from the response
image_url = response.data[0].url
print(image_url) # Printing the URL of the generated image
Note:- For dall-e-3, only n=1 is supported.
Whisper Models
from openai import AzureOpenAI # Importing the AzureOpenAI class
azure_endpoint = 'https://api.kadal.ai/proxy/api/v1/azure'
lm_key = 'YOUR_LM_KEY'
api_version = "2024-02-15-preview"
# Initializing the AzureOpenAI client with the endpoint, API version, and API key
client = AzureOpenAI(
azure_endpoint=azure_endpoint,
api_version=api_version,
api_key=LM_PROXY_KEY
)
# Opening the audio file that you want to transcribe
audio_file = open("sample.mp3", "rb")
# Making a request to transcribe the audio using the Whisper model
transcription = client.audio.transcriptions.create(
model="whisper", # Specifying the model to use (Whisper for audio transcription)
temperature=0, # Setting temperature to 0 for deterministic output (less randomness)
response_format="verbose_json", # The format in which you want the transcription response
file=audio_file # Passing the audio file to be transcribed
)
# Printing the transcribed text from the response
print(transcription.text)
Gemini Models
Generate Content
import requests # Importing the requests library to make HTTP requests
# API key for authentication with the service
lm_key = 'YOUR_LM_KEY'
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# Name of the model you want to use
model_name = 'gemini-1.5-pro'
# URL for the API endpoint to generate content using the specified model
url = f"{LLM_Gateway_SERVER_URL}/gemini/models/{model_name}:generateContent"
# Headers required for the API request
headers = {
"Content-Type": "application/json", # Setting the content type to JSON
"api-key": f"{lm_key}", # Including the API key for authentication
}
# The data payload for the API request
data = {
"contents": [
{
"role": "user", # Role of the content, indicating this is from the user
"parts": [{"text": "Hello World"}] # The text input from the user
}
]
}
# Making a POST request to the API to generate content
response = requests.post(url, headers=headers, json=data)
# Printing the JSON response received from the API
print(response.json())
Image requests
import base64 # Importing the base64 module to encode the image into Base64 format
import requests # Importing the requests library to make HTTP requests
# Function to encode an image into Base64
def encode_image(image_path):
"""
Encodes the image at the given path into a Base64 string.
Args:
image_path (str): Path to the image file to be encoded.
Returns:
str: Base64-encoded string of the image.
"""
with open(image_path, "rb") as image_file: # Open the image file in binary mode
# Read the file, encode its content to Base64, and decode it to a UTF-8 string
return base64.b64encode(image_file.read()).decode('utf-8')
# Encode the image at the specified path
base64_image = encode_image("sample.png")
# API key for authentication with the service
lm_key = 'YOUR_LM_KEY'
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# Name of the model you want to use
model_name = 'gemini-1.5-pro'
# URL for the API endpoint to generate content using the specified model
url = f"{LLM_Gateway_SERVER_URL}/gemini/models/{model_name}:generateContent"
headers = {
"Content-Type": "application/json",
"api-key": f"{lm_key}",
}
data={
"contents": [
{
"role": "user",
"parts": [
{
"inlineData": {
"mimeType": "image/jpg", #PNG - image/png, JPEG - image/jpeg, WebP - image/webp
"data": content
}
},
{
"text": "What's in this image?"
}
]
}
]}
# Making a POST request to the API to generate content
response = requests.post(url, headers=headers, json=data)
# Printing the JSON response received from the API
print(response.json())
Bedrock Anthorpic Models
import requests # Importing the requests library to make HTTP requests
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'YOUR_LM_KEY'
# Identifier for the specific model you want to use
modelId = "anthropic.claude-3-haiku-20240307-v1:0"
# Headers required for the API request
headers = {
"api-key": f"{lm_key}", # Including the API key for authentication
}
# The request body containing parameters for the API call
body = {
"anthropic_version": "bedrock-2023-05-31", # Specifies the version of the Anthropic API
"max_tokens": 512, # The maximum number of tokens to generate in the response
"messages": [
{
"role": "user", # Role indicating this message is from the user
"content": "say my name bot." # The text input from the user
}
]
}
# Making a POST request to the API to generate a response from the model
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/anthropic?modelId={modelId}",
headers=headers,
json=body
)
# Check for a successful response from the API
if response.status_code == 200:
data = response.json() # Parse the JSON response
print(data) # Print the response data
else:
# Print an error message if the API call fails
print(f"Error: API call failed with status code {response.status_code}, {response.text}")
Bedrock Llama Models
import requests
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'Your_LM_Key'
# Identifier for the specific model you want to use
modelId = "meta.llama3-1-8b-instruct-v1:0"
headers = {
"api-key": f"{lm_key}", # Including the API key for authentication
}
# The request body containing parameters for the API call
body = {
'messages': [{'role': 'user', 'content': [{'text': 'Hello World'}]}],
'inferenceConfig': {'maxTokens': 512, 'temperature': 0.5, 'topP': 0.9},
'system': [{'text': 'This is a valid system text'}],
}
# Making a POST request to the API to generate a response from the model
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/llama?modelId={modelId}",
headers=headers,
json=body
)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Error: API call failed with status code {response.status_code} , {response.text}")
Bedrock Nova Models
text generation:
import requests
import json
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'Your_LM_Key'
modelId = "us.amazon.nova-lite-v1:0"
body = json.dumps(
{
"messages": [
{"role": "user", "content": [{"text": "Hello World"}]},
],
"inferenceConfig": {"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
"system": [{"text": "This is a valid system text "}],
}
)
headers = {"api-key": lm_key}
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/nova?modelId={modelId}",
headers=headers,
json=json.loads(body),
)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data)
else:
print(
f"Error: API call failed with status code {response.status_code} , {response.text}"
)
multimodel:
import requests
import base64
import json
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'Your_LM_Key'
modelId = "us.amazon.nova-lite-v1:0"
IMAGE_NAME = "sample.png"
with open(IMAGE_NAME, "rb") as f:
image = f.read()
encoded_image = base64.b64encode(image).decode("utf-8")
user_message = "what in this image describe the image also."
body = json.dumps(
{
"messages": [
{
"role": "user",
"content": [
{"text": user_message},
{"image": {"format": "png", "source": {"bytes": encoded_image}}},
],
}
],
"inferenceConfig": {"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
"system": [{"text": "This is a valid system text "}],
}
)
headers = {"api-key": lm_key}
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/nova?modelId={modelId}",
headers=headers,
json=json.loads(body),
)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data)
else:
print(
f"Error: API call failed with status code {response.status_code} , {response.text}"
)
documents Input
import requests
import base64
import json
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'Your_LM_Key'
modelId = "us.amazon.nova-pro-v1:0"
Docs_NAME = "sample.pdf"
with open(Docs_NAME, "rb") as file:
doc_bytes = file.read()
encoded_docs = base64.b64encode(doc_bytes).decode("utf-8")
user_message = "tell me the title of the document"
body = json.dumps(
{
"messages": [
{
"role": "user",
"content": [
{
"document": {
"format": "pdf",
"name": "DocumentPDFmessages",
"source": {"bytes": encoded_docs},
}
},
{"text": user_message},
],
},
],
"inferenceConfig": {"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
"system": [{"text": "This is a valid system text "}],
}
)
headers = {"api-key": lm_key}
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/nova?modelId={modelId}",
headers=headers,
json=json.loads(body),
)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data)
else:
print(
f"Error: API call failed with status code {response.status_code} , {response.text}"
)
Video Input
import requests
import time
import base64
import json
# Base URL for the Gateway server handling API requests
LLM_Gateway_SERVER_URL = 'https://api.kadal.ai/proxy/api/v1'
# API key for authentication with the service
lm_key = 'Your_LM_Key'
modelId = "us.amazon.nova-pro-v1:0"
Video_Name = "sample.mp4"
with open(Video_Name, "rb") as video:
video_bytes = video.read()
encoded_video = base64.b64encode(video_bytes).decode("utf-8")
user_message = "what in this video."
body = json.dumps(
{
"messages": [
{
"role": "user",
"content": [
{"text": user_message},
{"video": {"format": "mp4", "source": {"bytes": encoded_video}}},
],
},
],
"inferenceConfig": {"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
"system": [{"text": "This is a valid system text "}],
}
)
headers = ({"api-key": lm_key},)
response = requests.post(
f"{LLM_Gateway_SERVER_URL}/bedrock/v1/messages/nova?modelId={modelId}",
headers=headers,
json=json.loads(body),
)
# Check for successful response
if response.status_code == 200:
data = response.json()
print(data)
else:
print(
f"Error: API call failed with status code {response.status_code} , {response.text}"
)
Responses:
| Status Code | Description | Content-Type |
|---|---|---|
| 200 | Successful | application/json |
| 400 | Bad Request | application/json |
| 401 | Unauthorized | application/json |
| 403 | Forbidden | application/json |
| 404 | Resource Not Found | application/json |
| 422 | Validation Error | application/json |
| 500 | Internal Server Error | application/json |
📞 Contact Us
If you have any questions, feedback, or need support, feel free to reach out to us through Email:
🔑 LM-API Key Access
To access and integrate with our Language Model (LM) APIs, you will need a valid LM-API key.
📣 Please contact your LM Administrator to request or retrieve your API key.
Access to the LM-API is restricted and managed to ensure proper usage and compliance with organizational policies.
If you're unsure who your LM Administrator is, please reach out to the support team and we'll assist you in connecting with the right person.
Thank you for working with us!